Combining AI with Formal Verification for Efficient Migration of Legacy Code
Advanced techniques for deploying and optimizing large language models on resource-constrained edge devices without compromising performance.
TL;DR
In this blog post, we present our LLM-based approach, called LLMLift, that approaches the problem of legacy code migration. LLMLift automatically translates input programs, written in various source languages (Java, C, and C++), into different target languages that then enables running those programs on the latest hardware platforms. LLMLift develops a formal verification based method to verify LLM outputs, which could be incorrect. In short, LLMLift is our first neuro-symbolic system for automatic code migration.
In the previous blog post we discussed Tenspiler — our collaborative project with Prof. Alvin Cheung from University of California at Berkeley — that developed a formal approach to the problem of migrating legacy code to domain-specific languages (DSL) of newer hardware (aka code transpilation problem). In the article, we also covered why code transpilation is an important business as well as technology problem in the context of performance, security, and maintenance of legacy code. To summarize, Tenspiler leverages a program synthesis framework called Metalift to build a code transpilation system that migrates legacy C/C++ programs to AI-specific DSLs (such as PyTorch and TensorFlow). PyTorch and TensorFlow are some of the most popular DSLs to program the latest AI hardware (such as Nvidia H100 GPUs, AI-specific hardware accelerators such as Intel Gaudi3). More importantly, Tenspiler also verifies the correctness of the migrated code by developing an approach based on formal verification.
While working on the Tenspiler project we learned several insights that pointed to its limitations. We discuss two of them below.
- First insight was with respect to the practicality of a formal code transpilation system. Specifically, we learned that the amount of time taken by Tenspiler for migration is directly related to the complexity of the input as well as the output program. This is because Tenspiler leverages an enumerative search technique to find a target-language program that is semantically-equivalent to the source-language program (aka verified lifting). The search algorithm would naturally take more time as the size of the search space would grow, unless some search space pruning techniques (aka optimizations) are employed. Tenspiler, in fact, did employ several optimizations that pruned the size of the search space by orders of magnitude. Nevertheless, these optimizations were not enough to make the search tractable as the program complexity grew.
- Second insight: building these optimizations is non-negligible manual efforts (~1200 Lines of code in Tenspiler). Moreover, it requires considerable knowledge of the domain of the target-programs.
Limitations of Tenspiler led us to ponder if large language models (LLMs) can be applied to the problem of verified code transpilation — specifically, can LLMs translate a source-language program to a target-language program while also ensuring the correctness of the translation. Of course, we all know that LLMs can tackle complex programming tasks such as code generation, program repair, test case generation. And their performance on these programming tasks seem to improve almost day-by-day. Not to our surprise, we found that several research efforts [1, 2, 3] have already explored application of LLMs or AI models (in general) for the problem of code transpilation. For instance, TransCoder, an AI model developed by Meta AI research group, employs an unsupervised learning approach to translate programs between Python, Java, and C++. Their evaluation shows that TransCoder can achieve up to 90% accuracy in some cases. Nevertheless, none of these approaches guarantee correctness of translations — at best, TransCoder employs unit tests to check if the translated code is functionally equivalent to the input code. Several research works [4, 5], on the other hand, employ LLMs for formal verification by asking them to produce proof annotations (such as loop invariants) for the input program. The languages used to represent these annotations are however not the languages understood by existing formal verification tools (e.g., SMT-LIB), leading to challenges in formal verification. LLMs are not good at producing proof annotations in the languages of the verification tools because these languages are typically low-resource in the training datasets of LLMs.
In this project, we continued our collaboration with Prof. Alvin Cheung's research group at University of California at Berkeley to investigate if and how LLMs can be applied to the problem of verified code transpilation. As an outcome of the collaboration, we developed LLMLift, an LLM-based approach for verified lifting. LLMLift still follows the original idea of verified lifting, which consists of (1) translating a source-language program to a target-language program (typically a DSL) by first liftingthe source-language program to an intermediate language (IR) (aka synthesizing an IR program), (2) verifying the synthesized program, and (3) finally, translating the synthesized program to a target-language program using syntax-driven translation rules. As compared to the formal approach employed in Tenspiler, LLMLift employs an LLM with a few-shot prompting to synthesize an IR program (aka program summary) and the proof annotations (i.e., invariants). It then verifies the correctness of the synthesized program by translating both the program summary and the invariants to the language of the formal verification tools. The key insights that we exploit in LLMLift are: (1) LLMs seem to understand general-purpose languages such as Python well, and (2) as such using Python as the IR for verified lifting (by encoding the semantics of target-language operators in Python) would enable an LLM to produce better proof annotations, thereby mitigating the low-training data problem mentioned above.
At CodeMetal, we also believe that the future programming-assistance systems would most likely be neuro-symbolic in nature. That is, AI techniques with the assistance of formal methods can enable us to exploit the "best of both worlds", thereby mitigating the limitations of each other.
LLMLift: Verified Lifting with LLMs
We now describe the components of our LLMLift system shown below.

As we mentioned above, LLMLift uses Python as the IR for verified lifting by encoding the semantics of target-language operations as Python functions. As can be seen in the figure, we break down the step of generating a program summary (PS) and the invariants (INV) into two separate steps. Experimentally, we found that two separate steps are more effective in generating accurate program summary and invariants than a combined step.
Generating a Program Summary Using Zero-Shot Prompting
Given an input program in a source language, LLMLift first prompts an LLM to translate this input program into an IR program that uses target-language operators specified in the prompt. In other words, an LLM is expected to find an IR program that uses target-language operations and is also equivalent to the input program. Towards that end, LLMLift employs zero-shot prompting technique, where the prompt consists of following components:
- Task instruction: We ask an LLM using English to translate the input program into an IR program. We also add specific constraints such as using the specified target language operators only in the prompt.
- Target-language operators: Our prompt also contains encoding of all the target-language operators as functions in Python.
- Program specification: Research has explored different ways to represent program specifications such as test cases, bounded model checking, etc. In LLMLift, we keep it simple and provide the actual input program as a specification in the prompt. This choice also mitigates issues around the lack of training data for LLMs in the other forms of specifications.
LLMs may not generate the output in the format exactly as we want. Hence we add a parser to parse the output of an LLM and extract the program summary. Moreover, we also check that the generated program summary conforms with the restrictions imposed in the prompt, such as only using the target-language operators.
A sample program summary prompt is shown below.

Generating an Invariant Using One-Shot Prompting
As against the zero-shot prompting technique employed in the program summary prompt, we use one-shot prompting technique to generate invariants for the input program. Recall that for an input program containing loops, we need to generate predicates (called loop invariants) to prove its equivalence with the generated program summary. For programs that do not contain loops, we do not need to generate the invariants. As such, this step is performed based on the input program. The invariants are also well-structured – they contain an expression over loop indices and an expression that uses target-language operators only. This structured nature simplifies the invariant synthesis problem.
LLMLift's prompt for generating invariants closely resembles its prompt for generating the program summary. As such, we discuss the additional elements of the invariants prompt. Specifically, in addition to the elements of the program summary prompt, the invariants prompt contains:
- Program summary: We feed the program summary generated in the previous step as an input in the invariants prompt. This step ensures that the generated invariants correspond to the given program summary.
- Assertion: We also add an assertion at the end of the input program to check the equality of the return variable with the generated program summary.
- One example: As the concept and the structure of invariants may be relatively new to an LLM, we familiarize it with them by providing one example.
Similar to the program summary output processing step, we also parse the LLM's output of the invariant generation step.
Verifier
If both program summary and invariant generation steps succeed, then their outputs are expected to be in Python and contain only the operators of the target language. For the formal verification step, we have built syntax-driven translation rules to translate both the program summary and the invariants in the language required by formal verification tools. If the verification fails, we restart the pipeline by asking an LLM to generate yet another candidate for the program summary.
Code Generator
A successful verification means that LLMLift has found an IR program that is semantically equivalent to the input source-language program. To generate the corresponding target-language program, LLMLift employs syntax-driven translation rules that map target-language operators from the IR program into the syntax of the target language. We found that Python's structured syntax simplifies the mapping process considerably.
Experimental Evaluation
The aim of our experimental evaluation was to measure: 1) how many of the input programs can LLMLift translate to different target languages (DSLs) within a reasonable time, 2) how fast it can synthesize/translate those programs to those languages, and 3) how does LLMLift compare with the existing formal approaches for code transpilation?
Experimental Setup
Input programs. We applied LLMLift to translate real-world C, C++, and Java programs to four distinct target languages belonging to different application domains. We show the transpilation problems, their source and target languages and their domains below.
Competing formal tools. As a competing formal tool that is capable of solving a given transpilation problem, we chose Metalift for the Java-to-MapReduce, C-to-switchISA, and C++-to-TensIR problems. For the C++-to-TACO problem, we used C2TACO tool developed recently in 2023.
Software and configurations. For the sake of experiments, we used GPT-4 model (via their APIs) as the LLM for generating program summaries and invariants. We set its temperature to 0.7.
Synthesis config. For the synthesis phase, we allowed the budget of 50 queries for the program summary generation and 10 queries for the invariants generation.
Experimental results
Overall, LLMLift could translate all of the 138 programs into respective target-languages.
Number of transpiled programs
As discussed before, formal transpilation tools (such as Tenspiler) are typically unable to transpile complex programs within a reasonable time. Towards that end, we decided to subject LLMLift to transpile the same set of programs. For this experiment, we allowed a timeout of 1hr for Metalift and 90 mins for C2TACO (as used in their original evaluation).
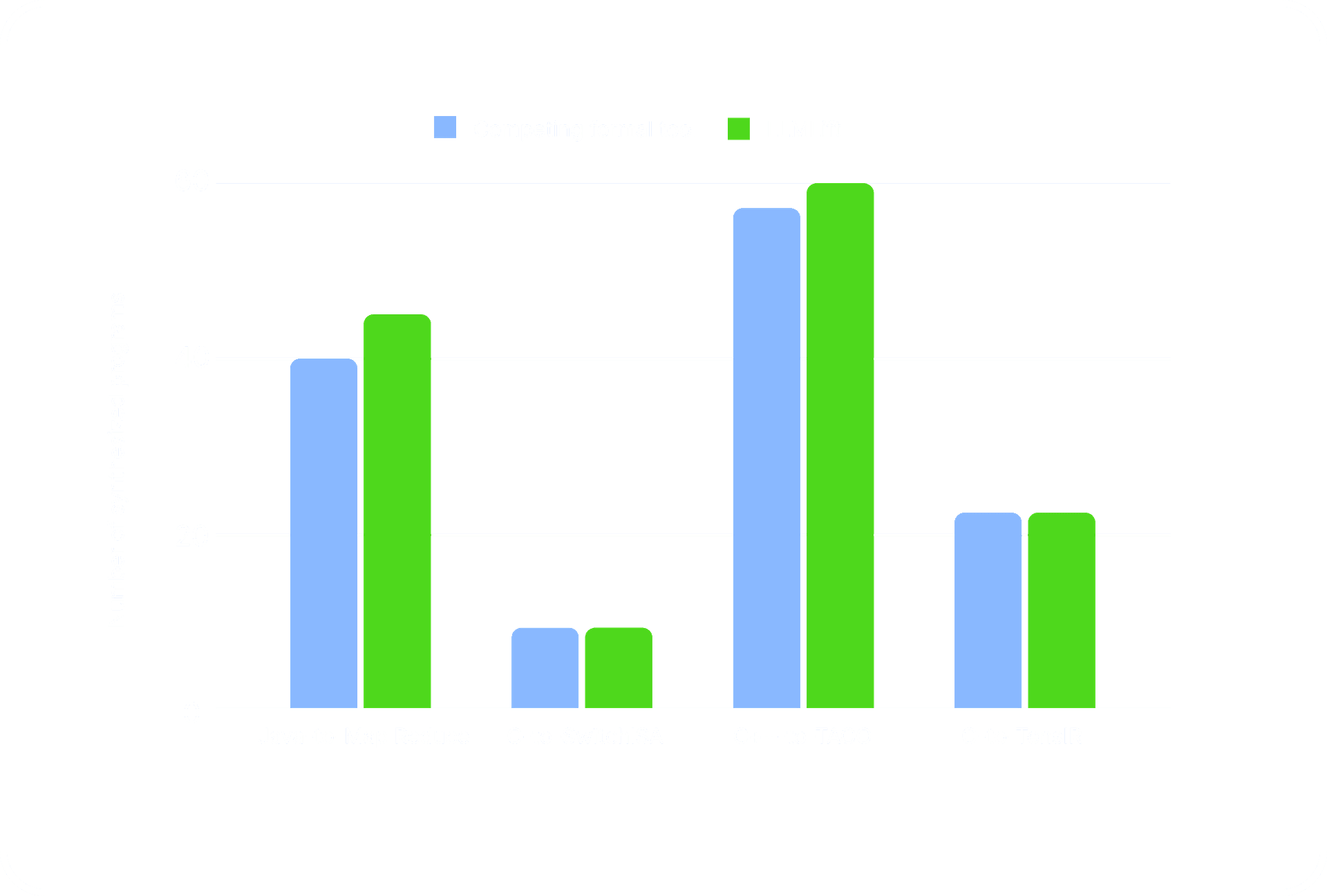
Fig 3 shows the number of programs transpiled by LLMLift as well as a competing formal tool for various transpilation problems. As can be seen, LLMLift is able to transpile the same or more number of programs than the competing formal tool. Specifically, Metalift times out on 5 out of 45 programs for the Java-to-MapReduce problem, while LLMLift transpiles 44 of those 45 programs. Similarly, for the C++-to-TACO problem, C2TACO is able to transpile 57 out of 60 programs, while LLMLift is able to transpile all 60 of them. C2TACO could not transpile 3 programs as they contained program expressions of depth greater than 4, so much so that even a timeout of 1 day would not suffice C2TACO to transpile those programs.
In short, LLMLift could transpile complex programs that the competing formal tools failed to transpile —- underscoring the ability of LLMs in searching the target-language programs for a given input program quickly.
Transpilation timings
In addition to the number of programs that LLMLift could transpile, we also wanted to compare its transpilation time with the competing formal tools.
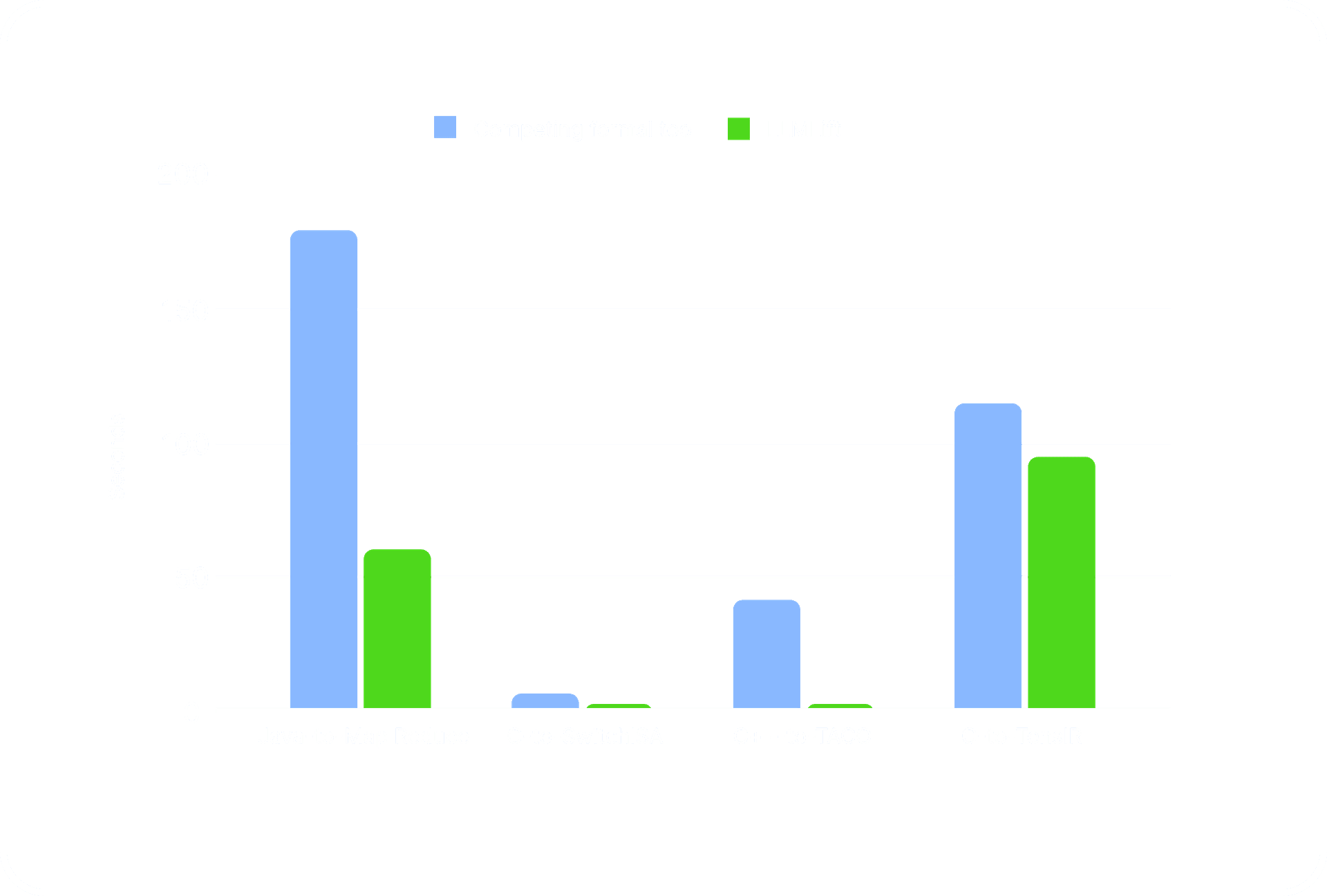
Overall, we can see that LLMLift is able to solve the transpilation problems considerably more quickly (up to 20X) than a competing formal tool.
Efforts to build the transpiler
Recall that formal transpilation tools such as Metalift require a user to provide a description of the search space for the program summary and invariants generation. Based on our experiments with Metalift and Tenspiler we found that such descriptions are not enough — optimizations to prune the search are crucial to keep the search problem tractable and are required to be implemented by the user as well.
While experimenting with LLMLift for the four transpilation problems, we found that an LLM can eliminate the need for manual implementation efforts considerably. Specifically, for all four problems both Metalift and C2TACO required ~1000 LoC for the search space descriptions as well as the optimizations. LLMLift based transpilers did not require such descriptions and were fast to develop.
Conclusion
In this article, we presented our AI-based code transpilation system named LLMLift. We built LLMLift from the insights that we learned from our prior formal methods based transpilation system named Tenspiler.
Our results show that LLMLift could transpile programs belonging to different application domains more quickly than competing formal transpilation tools. More importantly, LLMLift requires considerably less effort to build transpilers and can transpile complex programs that are otherwise out of the reach of existing formal transpilation tools.
All the benefits of an AI based transpilation system would be of no use if the generated target programs are incorrect. Towards that end, this work also demonstrates that it is indeed possible to formally verify AI generated output —- thereby allowing us to exploit the best of AI and formal verification methods at the same time!
Next Steps
In this article, we presented our work, in collaboration with University of California at Berkeley, that combines AI techniques with formal verification methods (aka neuro-symbolic approach) to the problem of migrating legacy code to newer hardware devices and their programming languages. During the course of this work, we realized that it could sometimes be difficult or time-consuming to get LLMs to generate the output exactly as we want. This could partly be because of their unexplainable nature. We also believe that this could be because of a lack of appropriate and informative feedback from our output verifier to the LLM. Towards the end we would like to explore if and how better-quality feedback could improve the performance of LLMLift.
References
[1] Raymond Li, et al. Starcoder: may the source be with you!, 2023. https://arxiv.org/abs/2305.06161
[2] Yujia Li, et. al. Competition-level code generation with alphacode. Science, 378(6624):1092–1097, 2022. http://dx.doi.org/10.1126/science.abq1158.
[3] Baptiste Rozière, et al. Code llama: Open foundation models for code. 2024. https://arxiv.org/abs/2308.12950
[4] Saikat Chakraborty, et al. Ranking llm-generated loop invariants for program verification. 2023. https://arxiv.org/abs/2310.09342
[5] Kexin Pei, et al. Can large language models reason about program invariants? In Proceedings of the 40th International Conference on Machine Learning. 2023. https://proceedings.mlr.press/v202/pei23a.html
[6] Anirudh Sivaraman, et al. Packet transactions: High- level programming for line-rate switches. InProceedings of the ACM SIGCOMM Conference, 2016. https://dl.acm.org/doi/10.1145/2934872.2934900
[7] Fredrik Kjolstad, et al. The tensor algebra compiler. Proc. ACM Program. Lang., 1(OOPSLA) 2017. http://doi.acm.org/10.1145/3133901. http://tensor-compiler.org/.
[8] Jie Qiu, et al. Tenspiler: A verified lifting-based compiler for tensor operations. 2024. https://arxiv.org/abs/2404.18249
Related Research
The Trust Problem Has Shifted: What Formal Verification Can and Cannot Guarantee About AI-Generated Code
A clear-eyed technical assessment of formal verification for AI-generated code: which approaches are credible, what barriers remain, and where the market will emerge first.
The Real Cost of Leaving NVIDIA
What Automated Transpilation Actually Costs, and What It Doesn't